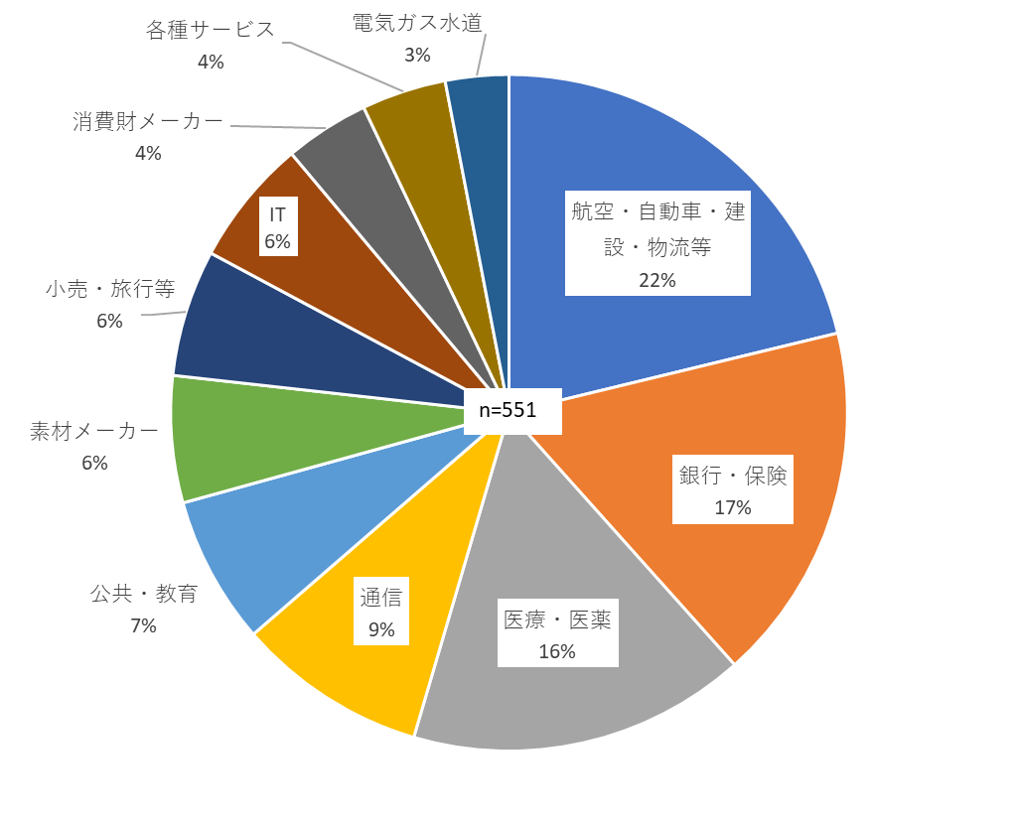
Hidden truth of process mining(1)
English follows Japanese Before proofread.
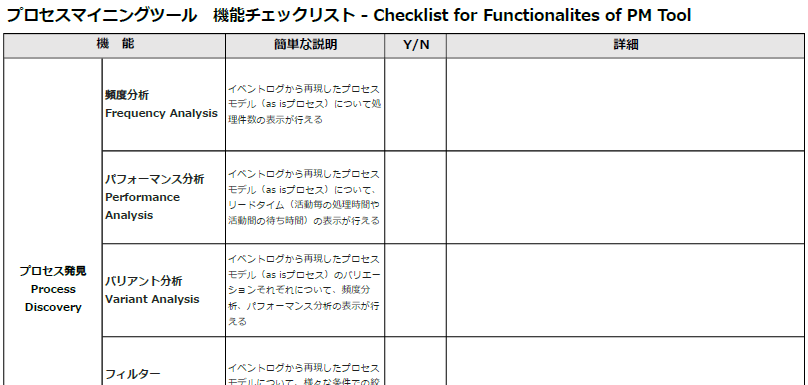
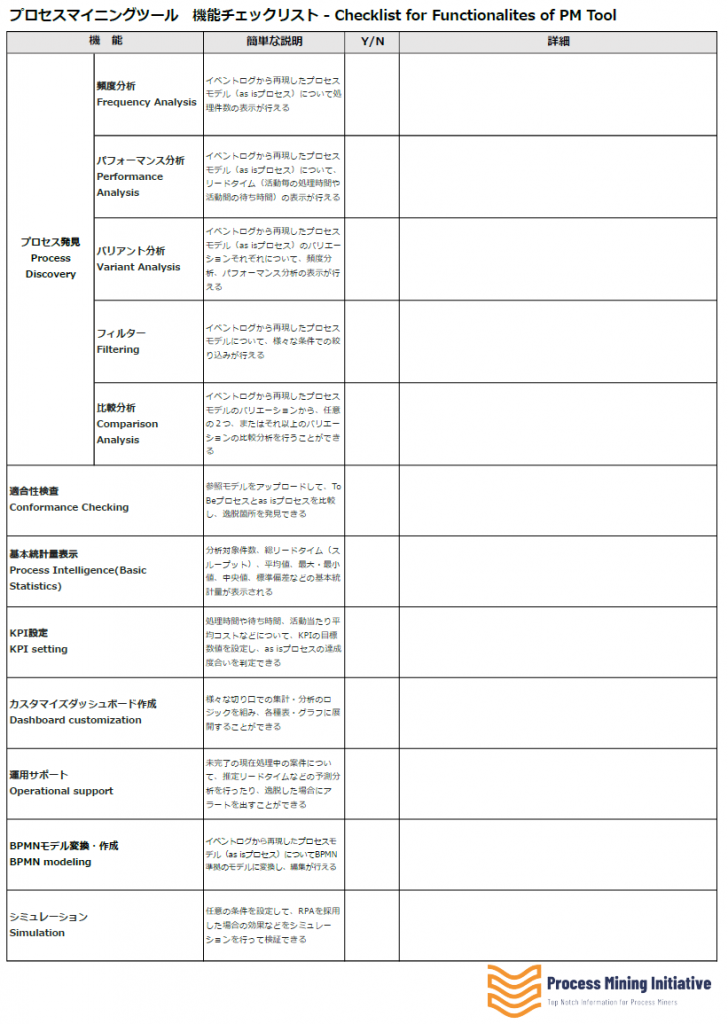
最近、業務改革の切り札としてプロセスマイニングに対する関心がますます高まっています。多くの人は、プロセスマイニングのデモで示される「プロセスモデル」、すなわち、イベントログから自動的に作成された業務フローチャート図を目にして「おおっ、すごい」と感嘆の声をあげます。
業務プロセスを可視化するための従来のアプローチであるヒアリングやワークショップの大変さと比較して、ITシステムから抽出したデータから簡単にすばやく業務フロー図が描けるのはすばらしい、と皆さんお感じになるわけですね。
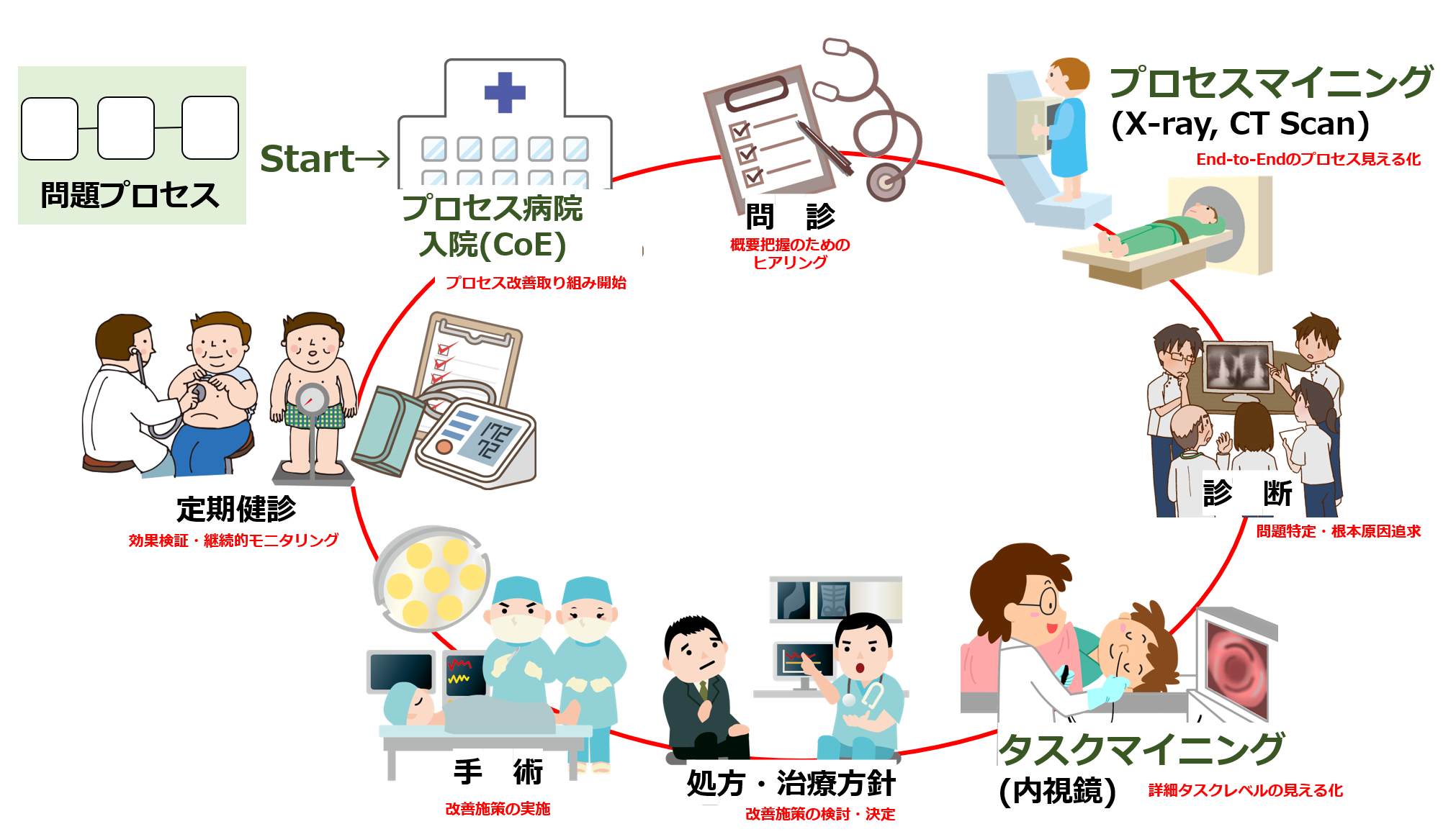
ただ、何事にも明るい側面(Bright side)と、暗い側面(Shadow side)があるものです。プロセスマイニングツールを操作して、今まで見えなかった業務プロセスの流れや業務と担当者との関係が図表でわかりやすく示されるところは「明るい側面」です。一方、導入の心理的ハードルを上げてしまうために、あまり語られない「暗い側面」があります。
暗い側面は実は2つあります。プロセスマイニングツールを操作して実際の分析を行う段階の前に必要な業務である「データ前処理」、そして実際の分析の後に行う「分析結果の評価・解釈」の2つのフェーズです。
プロセスマイニングツールを操作して、ビジュアルな画面を切り替えるのは簡単で楽しいものです。一方、データ前処理、および分析結果の評価・解釈は多大な労力を要します。しかし、プロセスマイニングを通じて業務改革を成し遂げるためには避けて通るわけにはいかないフェーズ。このことは、プロセスマイニングの不都合な真実と言えるでしょう。
今回は、まず、プロセスマイニング分析の前工程である「データ前処理」について解説します。
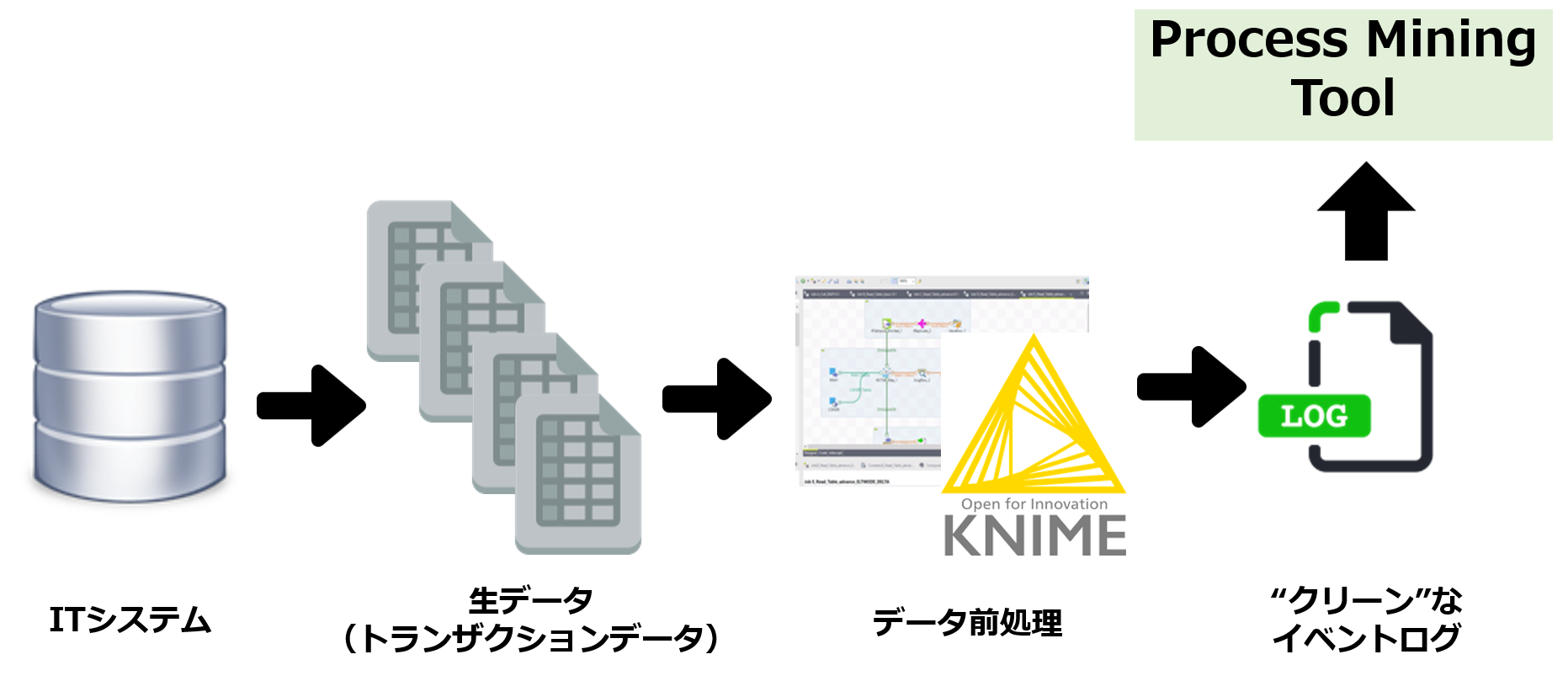
プロセスマイニングの対象とする業務プロセスを決定したら、その業務プロセスを遂行しているITシステムから、必要なデータを抽出するわけですが、抽出されたデータ(生データ:トランザクションデータ)をそのままプロセスマイニングツールにアップロードすることはできません。
というのも、プロセスマイニングツールにアップロードするファイルは、ノイズなどが除去され、所定のデータ項目が揃ったクリーンなファイルに一本化する必要があるからです。
一般に、ITシステム内のDBから抽出されたデータは年度単位でファイルが分かれていたり、トランザクションファイルとマスターファイルが分かれていたり、データの抜け漏れ(ブランク)や文字化けがあったりと、要するに汚れたデータ、ダーティデータです。
このような複数(しばしば数十本)のダーティデータをクリーンにし1つのデータファイル=クリーンなイベントログに加工する作業が「データ前処理」です。
データ前処理をどのように行うかの説明は別記事で取り上げますが、例えば、ブランクが存在するデータについては一括削除したり、なんらかの補正値を入力したりします。こうした前処理作業を数十万~数百万件の生データに対して行うため、基本的にはデータ前処理のためのツール「ETL」を用います。
ETLはExtract, Tranform, Loadの頭文字を取ったものですが、文字通りデータ抽出からデータ変換(加工)、他のツールへのアップロード、さらには分析機能も持つ多機能なツールですが、プロセスマイニングにおいてはもっぱらデータ変換(加工)に活用します。
私がお勧めしているETLは、「KNIME(ナイム)」というオープンソースのツールです。日本語ローカライズはされていませんが、なんせ無料ですし、直感的な操作を行うことができる非常に優れたツールです。
KNIMEであれば、様々なデータ加工をノンプログラミングで行うことができるため、エンジニアでなくともデータ前処理を実行可能です。もちろん、エンジニアの方がデータ前処理を行うのであれば、SQL、Python、Rなど得意なスクリプトでデータ加工処理を行えば、KNIMEより高速に処理ができるでしょう。
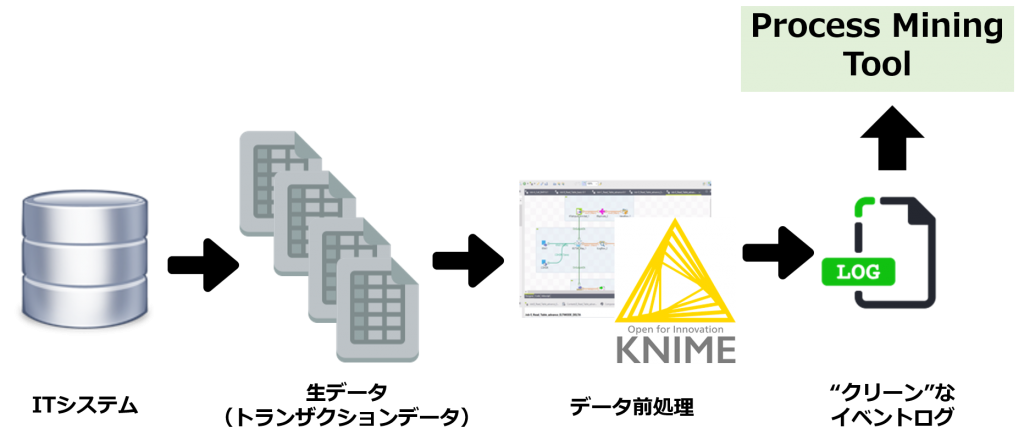
データ前処理の基本的な流れ
データマイニングプロジェクトでは、しばしば、データ前処理にプロジェクト工数の8割ほどが費やされると言われますが、プロセスマイニングプロジェクトでも同様に、データ前処理がプロジェクト成功の鍵を握っています。きちんとしたデータが準備されてこそ、プロセスマイニング分析、また分析結果の評価・解釈が意味のあるものになるからです。
Recently, there has been increasing interest in process mining as a trump card for business innovation. Many people marvel at the “process model” shown in the process mining demos, or business flow charts automatically created from event logs, saying, “Oh, my God.”.
In contrast to the challenges of traditional approaches to visualizing business processes such as interviews and workshops, you find it great to be able to draw business flow diagrams easily and quickly from data extracted from IT systems.
But everything has a bright side (Bright side) and a dark side (Shadow side). When you operate the process mining tool, the flow of business processes and the relationship between business and the person in charge, which has not been seen until now, are shown clearly in the diagram, is “bright side”. On the other hand, there is a “dark side” that is rarely talked about because it raises the psychological hurdle of introduction.
There are actually two dark sides. There are 2 phases: “data preprocessing” which is the work required before the stage of operating the process mining tool and performing the actual analysis, and “Evaluation and interpretation of analysis results” which is performed after the actual analysis.
It’s easy and fun to navigate through process mining tools and switch between visual screens. On the other hand, data preprocessing and the evaluation and interpretation of analysis results require a great deal of labor. However, this is a phase that cannot be avoided in order to achieve business reform through process mining. This is an inconvenient truth of process mining.
In this article, I will first explain “data preprocessing” which is a pre-process of process mining analysis.
Once a business process to be subjected to process mining is determined, necessary data is extracted from the IT system executing the business process, but the extracted data (raw data: transaction data) cannot be directly uploaded to the process mining tool.
This is because the files to be uploaded to the process mining tool need to be unified into a clean file with all the necessary data items.
In general, the data extracted from the DB in the IT system is dirty data or dirty data, for example, the file is divided by the year, the transaction file and the master file are separated, and there are omissions of data (Blank) and garbled characters.
“data preprocessing” is the process of cleaning such multiple (Often dozens) dirty data and processing them into 1 data file = clean event log.
We’ll discuss how to do this in a separate article, but for example, you might want to delete all data with blanks or enter some correction. To perform these preprocessing operations on 100,000 to 1 million raw data items, a data preprocessing tool “ETL” is basically used.
ETL, which stands for Extract, Tranform, and Load, is a multi-functional tool that literally extracts data, transforms it (Machining), uploads it to other tools, and even provides analysis capabilities, but is used exclusively for data transformation (Machining) in process mining.
The ETL tool I recommend is an open source one called “KNIME”. It’s not localized in Japanese, but it’s free and very intuitive.
KNIME can perform various data processing without programming, so even non-engineers can perform data preprocessing. Of course, if your engineers preprocess data, they can do it faster than KNIME by using SQL, Python, R, or other scripts that you’re good at.
In data mining projects, it is often said that data preprocessing consumes about 80% of the project effort. Process mining analysis and the evaluation and interpretation of analysis results become meaningful only when proper data is prepared.